
Nel panorama in costante evoluzione dell’intelligenza artificiale, i modelli linguistici di grandi dimensioni (LLM) come GPT-4 e Llama hanno ricevuto notevole attenzione per le loro straordinarie capacità di elaborazione e generazione del linguaggio naturale, tuttavia, i modelli linguistici di piccole dimensioni (SLM) stanno emergendo come un contrappeso fondamentale nella comunità dei modelli di IA, offrendo un vantaggio unico per casi d’uso specifici.
AMD è entusiasta di presentare il suo primo modello linguistico di piccole dimensioni, AMD-135M, con decodifica speculativa. Questo lavoro dimostra l’impegno verso un approccio aperto all’IA, che porterà a un progresso tecnologico più inclusivo, etico e innovativo, contribuendo a garantire che i suoi benefici siano condivisi più ampiamente e che le sue sfide siano affrontate in modo collaborativo.
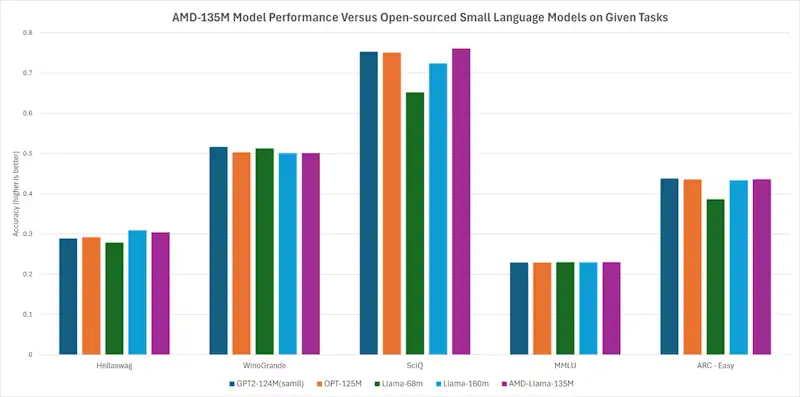
AMD-135M: Primo Modello Linguistico di Piccole Dimensioni di AMD
AMD-135M è il primo modello linguistico di piccole dimensioni della famiglia Llama, addestrato da zero su acceleratori AMD Instinct™ MI250 utilizzando 670 miliardi di token, suddiviso in due varianti: AMD-Llama-135M e AMD-Llama-135M-code.
- Pre-allenamento: Il modello AMD-Llama-135M è stato addestrato da zero con 670 miliardi di token di dati generali in sei giorni utilizzando quattro nodi MI250.
- Ottimizzazione del Codice: La variante AMD-Llama-135M-code è stata perfezionata con ulteriori 20 miliardi di token di dati di codice, richiedendo quattro giorni sullo stesso hardware.
Il codice di addestramento, il dataset e i pesi per questo modello sono open source, in modo che gli sviluppatori possano riprodurre il modello e contribuire all’addestramento di altri SLM e LLM.
Ottimizzazione con Decodifica Speculativa
I modelli linguistici di grandi dimensioni solitamente adottano un approccio autoregressivo per l’inferenza. Tuttavia, una delle principali limitazioni di questo metodo è che ogni passaggio in avanti può generare solo un singolo token, risultando in una bassa efficienza di accesso alla memoria e influenzando la velocità complessiva dell’inferenza.
L’emergere della decodifica speculativa ha risolto questo problema. Il principio fondamentale consiste nell’utilizzare un piccolo modello di bozza per generare un insieme di token candidati, che vengono poi verificati dal modello target più grande. Questo approccio consente a ciascun passaggio in avanti di produrre più token senza compromettere le prestazioni, riducendo significativamente il consumo di accesso alla memoria e consentendo miglioramenti di velocità di diversi ordini di grandezza.
Accelerazione delle Prestazioni di Inferenza
Utilizzando AMD-Llama-135M-code come modello di bozza per CodeLlama-7b, abbiamo testato le prestazioni di inferenza con e senza decodifica speculativa sull’acceleratore MI250 per i data center e sul processore Ryzen™ AI (con NPU) per i PC AI. Per le configurazioni specifiche che abbiamo esaminato utilizzando AMD-Llama-135M-code come modello di bozza, abbiamo osservato un’accelerazione delle prestazioni sull’acceleratore Instinct MI250, sulla CPU AI Ryzen e sulla NPU AI Ryzen rispetto all’inferenza senza decodifica speculativa. Il modello AMD-135M SLM stabilisce un flusso di lavoro end-to-end, comprendendo sia l’addestramento che l’inferenza, su selezionate piattaforme AMD.
Fonte: AMD










0 commenti